
What is Text Extraction and Crawling in dox2U?
dox2U’s “Text Extraction'' not only makes searching for documents easy but also intelligent. We use Optical Character Recognition (OCR) & ICR (Intelligent Character Recognition) to analyze your data and convert it into a workable format for you so that it can be easily analyzed, shared, and worked with.
dox2U is engineered to make working on all types of formats seamless and convenient. For this purpose, dox2U provides the functionality of Crawling and Text Extraction. In simpler words; through crawling you can pull out text from non-image-based, workable formats like .doc, .docx, .txt, etc. On the other hand, dox2U is powerful enough to extract text from image-based, non-editable formats like PDF, JPG, etc., as well! This is achieved through the means of ‘Text Extraction’.
📓Things to be noted
- Searchable PDFs are created only in the case of Text Extraction, which can be easily retrieved by running a simple search on your Workspace.
- The functionality of crawling the text of all workable document formats (.doc, .docx, .txt, .rtf, etc.) is a very useful tool and is available across all Workspaces no matter which subscription plan they are subscribed to.
- The functionality of text extraction and downloading the text and Searchable Doc for all image-based files (.pdf, .png, .jpeg, .jpg, .tiff, .tif, .gif, .bmp etc) is another useful tool and is only available in Workspaces that are subscribed to Pro plans. Upgrade now or contact Sales [mailto:] to learn more.
Are Crawling and Text Extraction Safe?
Privacy and security have always been dox2U’s highest priority. Our features have been carefully engineered to provide you with the most secure experience possible. When we parse through your documents to provide you with the searchable PDFs and Extracted Text, we ensure that everything you upload remains for your eyes only and the extracted data is held in highly secure & encrypted databases.
What all formats are supported during Crawling and Text Extraction?
dox2U supports the following editable and non-editable file formats for Crawling and Text Extraction respectively.
| Supported Editable Formats | Supported Non-Editable Format |
| JPG/JPEG | |
| RTF | BMP |
| TXT | PNG |
| DOC | GIF |
| DOCX | TIFF |
| ODT | TIF |
View Text Extraction Status, Extracted Text, and Searchable Doc
A soon as you upload a document of editable nature (.txt, .doc, .txt, etc), dox2U Crawls these by default instantaneously. For Image-based formats (.jpg, .jpeg, .pdf, etc), Text Extraction begins immediately depending on the plan you are subscribed to.
1. View Text Extraction Status
You will be able to see the status of extraction/crawling, on your “My Queue” or “Workspace Queue” pages adjacent to the file name through an indicative icon.

| Status of Text Extraction | Implication | Representative Icon |
| 1. Completed | Text extraction has been successfully completed by dox2U |  |
| 2. In-Queue | Our engine has not yet initiated the process of Text Extraction; will begin soon. |  |
| 3. Failed | There was an error most likely due to an unsupported format uploaded by you. Please contact dox2U support from within your Workspace either using the life ring button (for direct chat support) or via the ‘Help Support’ button given on the action bar; through which you can send us your feedback in detail. |  |
2. View Extracted Text
To view your extracted text (only in image formats), you may follow these steps:
Step 1: Open the document by clicking on it
Step 2: Click on the ‘View Extracted Text’ option that is provided in the Text Extraction box towards the left-hand corner of the visible screen.

Step 3: Your extracted text as per the selected language will appear on the screen,
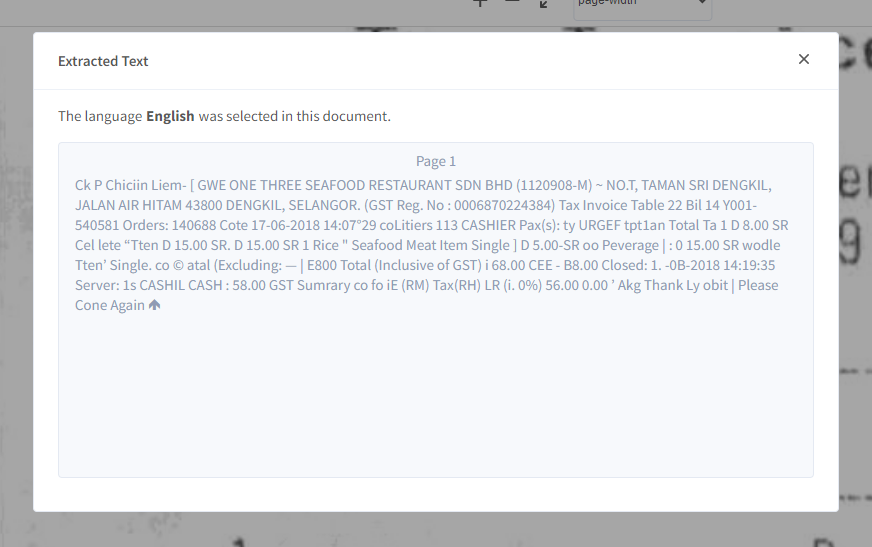
3. View Searchable Document
To view your searchable document (only for images), you may follow these steps:
Step 1: Open the document by clicking on it.
Step 2: In the View mode, click on the “Searchable Doc” button. The Searchable PDF generated by dox2U can be found in this tab.
💡 Using the Searchable Doc, you can perform various actions like copying information from the PDF and searching within the PDF to locate particular words or phrases.
📓Things to note
- In the case where your original file is already editable, non-image based format, for e.g. file formats like .txt, .doc, etc, the Original Doc that you see is the same as your Searchable Doc and is labeled “Original (Searchable) doc.”
- In the case where the original file is a non-editable image format, for e.g. PDF, jpg, etc, a separate Searchable Doc is generated and can be accessed using the steps outlined above.
- You can always choose to re-parse your document if a language is missed or if some of the text is not extracted. Read more about this here
Download Extracted Text and Searchable Doc
To download the Extracted Text or Searchable PDF from View, Edit, or Verification modes, follow these steps:
Step 1: Use the “Download” button 
Step 2: In the dialogue box that pops us, choose either the Searchable PDF or Extracted Text format. Press “Download” to continue with the download process or press “Cancel” to abort.
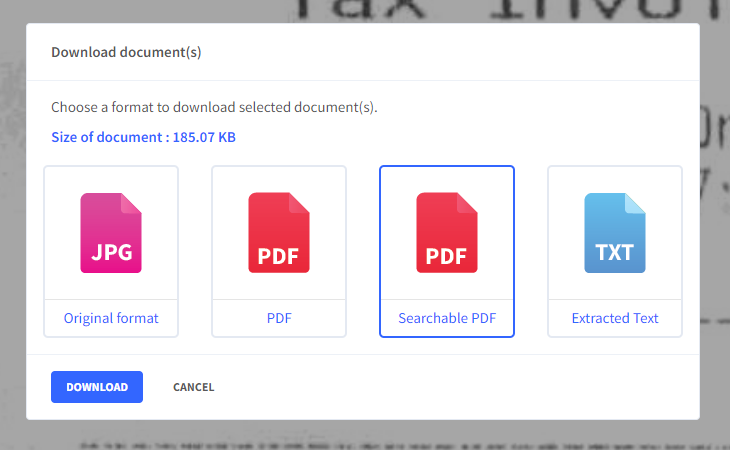
📓NOTE:
- You can only download docs where you are the Owner. To download a doc that is shared with you but owned by someone else, you must have the “Download and Print” right enabled. Understand rights in dox2U.
- Searchable Doc & Extracted text download is available ONLY for non-editable formats.

Sending a Document for Text Extraction with a Different Language
dox2U supports text extraction from image-based formats (like jpg, jpeg, pdf, etc) in over 160 human languages with high accuracy. The language selected by you during upload is used for parsing your document and converting it into workable digital formats.
In case you accidentally selected the wrong language during upload or want to re-run text extraction on your document using a different language, dox2U lets you select a different language and send the document for reparsing.
Let us see how:
Step 1: Open the document in an Edit mode by either using the menu 

Step 2: Click on the ‘View Extracted Text/Change Language’ option that is provided in the Text Extraction box towards the left-hand corner of the visible screen.

Step 3: Your extracted text as per the selected language will appear on the screen.
Step 4: In case you want to reparse your document, choose a language from the dropdown menu and hit “Reparse”. Your document will be reparsed according to your newly selected language.
📓Things to note
- When you send a document for reparsing with a new language, the Extracted Text & Searchable PDF are regenerated according to the newly selected language.