
View Text Extraction Status, Extracted Text, and Searchable Doc
A soon as you upload a document of editable nature (.txt, .doc, .txt, etc.), dox2U Crawls these by default instantaneously. For Image-based formats (.jpg, .jpeg, .pdf, etc.), Text Extraction begins immediately depending on the plan you are subscribed to.
View Text Extraction Status
As soon as you upload a document (both editable or non-editable), the crawling and text extraction starts automatically. You will be able to see the status of extraction/crawling, on your “My Queue” or “Workspace Queue” pages adjacent to the file name through an indicative icon.

| Status of Text Extraction | Implication | Representative Icon |
| Completed | Text extraction has been successfully completed by dox2U |

|
In-Queue
| Our engine has not yet initiated the process of Text Extraction; will begin soon. |

|
Failed
| There was an error most likely due to an unsupported format uploaded by you. Please contact dox2U support from within your Workspace either using the life ring button (for direct chat support) or via the ‘Help Support’ button given on the action bar; through which you can send us your feedback in detail. |

|
View Extracted Text
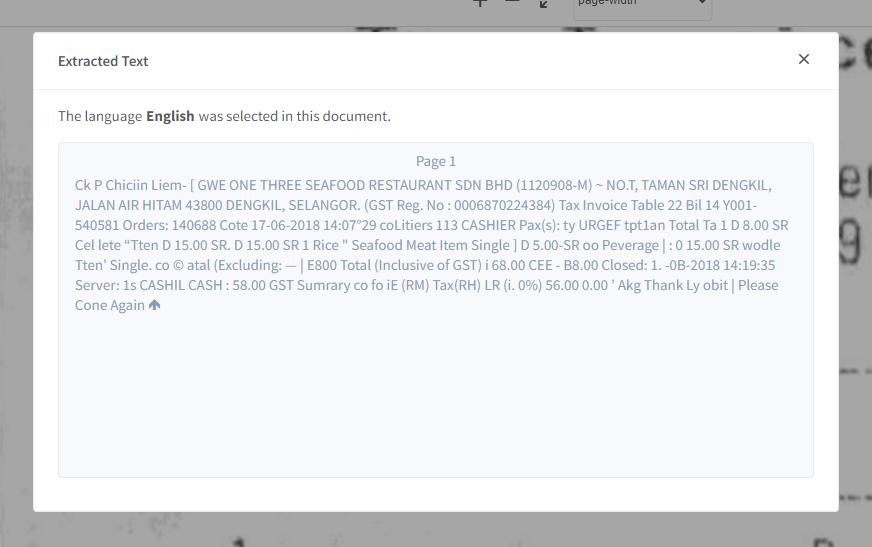
To view your extracted text (only in image formats), you may follow these steps:
Step 1: Open the document by clicking on it
Step 2: Click on the ‘View Extracted Text’ option that is provided in the Text Extraction box towards the left-hand corner of the visible screen.

Step 3: Your extracted text as per the selected language will appear on the screen
View Searchable Doc
To view your searchable document (only for images), you may follow these steps:
Step 1: Open the document by clicking on it.
Step 2: In the View mode, click on the “Searchable Doc” button. The Searchable PDF generated by dox2U can be found in this tab.
💡 Using the Searchable Doc, you can perform various actions like copying information from the PDF and searching within the PDF to locate particular words or phrases.
📓Things to note
- In the case where your original file is already editable, non-image based format, for e.g. file formats like .txt, .doc, etc., the Original Doc that you see is the same as your Searchable Doc and is labeled “Original (Searchable) doc.”
- In the case where the original file is a non-editable image format, for e.g. PDF, jpg, etc., a separate Searchable Doc is generated and can be accessed using the steps outlined above.
- You can always choose to re-parse your document if a language is missed or if some of the text is not extracted. Read more about this here